Puissance de calcul
Les Systèmes à hautes performances |
http://www.top500.org/ |
SMP ou symétrique multiprocesseurs
Une machine SMP est constituée de plusieurs machines qui pourront fonctionner simultanément et ainsi augmenter la capacité de traitement proportionnellement au nombre de processeurs implantés. Attention à ne pas confondre SMP et processeurs multicores qui sont des processeurs où sont gravés plusieurs cœurs (plusieurs unités de calculs) sur la même pastille de silicium. La technique SMP reste prépondérante dans les grands calculateurs (Linux, UNIX, mainframe) alors que la technique du multicore tend à s'étendre dans le monde Windows avec notamment la technologie Hyper-Treading1.
Clusters, MMP et Metacomputing |
|
| Les moyens pour parvenir à fournir de grandes puissances de calcul se font de plus en plus variés. Dans un premier temps, il s'est surtout agit de machines multiprocesseurs. Les solutions sous la forme de clusters (grappes d'ordinateurs) sont maintenant bien implantées et mettent en œuvre des systèmes à grande puissance de travail. On parle dès lors de clusters d'ordinateurs ou de MMP (machines massivement parallèles). Les ordinateurs qui composent une grappe sont appelés nœuds. L'objectif est de fournir une machine virtuelle capable d'exécuter une grande quantité d'opérations sur différents nœuds visibles de l'extérieur comme une seule entité. Ces opérations peuvent faire partie d'applications différentes sans que ce soit une obligation. Souvent, lorsqu’on parle de cluster ou de MMP, ce sont surtout des grappes d'ordinateurs dédiés à une application spécialement destinée à fonctionner sur plusieurs machines en même temps. Le fait d'ajouter des machines à la grappe d'ordinateurs permet d'augmenter (scalability) la capacité globale de traitement. Les applications doivent toutefois supporter le Multi Threading qui consiste, comme le SMP, à augmenter le Thread Level Parallelism, c’est-à-dire le parallélisme des threads 2 pour pouvoir en tirer partie de ce type de système. |
 Serveurs en grappe Serveurs en grappe© TICSIPD, 2010 |
|
Concernant les machines à hautes performances, les termes de clusters et MMP sont associés à des grappes de machines qui sont physiquement dans un même endroit. Le metacomputing ou cloud computing est une technique qui permet, grâce à l’interconnexion d’un très grand nombre de machines via Internet ou via un réseau distant, de fournir un supercalculateur virtuel utilisable par tous ceux qui y ont accès; chaque utilisateur ayant la possibilité de faire fonctionner ses propres applications via une API3 commune capable de tirer parti de cette architecture. |
© TICSIPD / fotolia, 2010 |

Cloud computing
 Cloud metacomputing
Cloud metacomputing
© TICSIPD, 2010
Clustering dédié à la puissance de calcul
Une finalité du clustering est l'augmentation de performance, l'autre étant dédiée à la disponibilité. Elle consiste à relier ensemble plusieurs ordinateurs afin de coupler la puissance de chacun (les nœuds) à l'ensemble du cluster. La scalability est assurée par ajout de nœuds supplémentaires au fur et à mesure de l’augmentation des besoins. Les nœuds supplémentaires peuvent être constitués de machines basiques à prix abordable4. Au fur et à mesure de l'évolution du matériel, il est possible de remplacer le matériel qui devient obsolète par du matériel plus compétitif. On peut ainsi adapter la puissance globale du cluster sans avoir à changer tout le matériel. En comparaison, un superordinateur n’est pas upgradable. Il a une durée de vie beaucoup plus limitée, en général entre 4 à 6 ans. Lorsqu’on parle de systèmes dédiés aux hautes performances, la littérature utilise souvent le terme cluster pour désigner le concept de load balancing. Un cluster dédié à la puissance de calcul est aussi résistant aux pannes.
Load balanced cluster
Le load balancing clustering, service à équilibrage de tâches, consiste à envoyer des requêtes vers différents nœuds exécutant tous la même application, partageant ainsi le travail entre les différents nœuds évitant d’avoir une machine surchargée. L’avantage d’un cluster load balanced est d’offrir un système à haute capacité de calcul, de disponibilité et surtout capable de monter en charge scalability. Le cluster crée un serveur virtuel qui envoie les différentes requêtes sur les différents nœuds qui le compose. Chaque nœud est configuré pour exécuter la même application et répondre aux requêtes du serveur virtuel. Ce type de cluster a toutes fois une caractéristique particulière, il n’a pas de disques partagés, ce qui signifie qu’à tout moment, chaque nœud possède une copie des données à traiter, donc des données statiques. L’utilisation d’une base de données en lecture uniquement serait possible, mais dès qu’on passe en écriture, le contenu devient dynamique donc impossible dans ce cas. En général, deux cartes réseau sont montées dans chaque nœud, une carte étant dédiée à la communication avec le serveur virtuel, une autre étant dédiée à l'accès LAN au serveur virtuel.
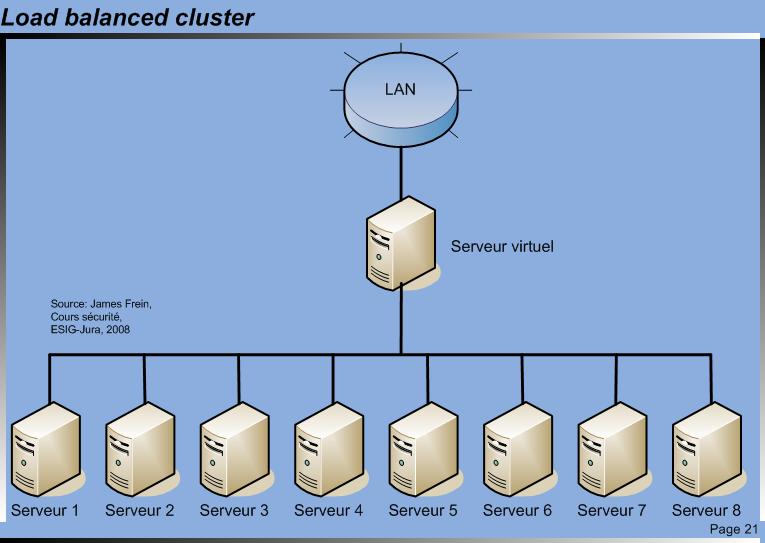 Load Balanced Cluster
Load Balanced Cluster
© TICSIPD, 2010
MMP Machines Massivement Parallèles
Par rapport à un cluster de type load balanced qui se compose généralement de quelques dizaines de nœuds au maximum, une machine massivement parallèle est constituée de centaines voire de milliers de nœuds. Physiquement, elle est présentée sous forme d'armoires qui peuvent recevoir de manière simple d'autres nœuds par ajout de cartes. Un réseau d'interconnexion spécifique est utilisé tandis que pour un cluster classique, c'est un réseau d'interconnexion classique qui est utilisé comme FDDI (Fiber Distributed Data Interface), Fast Ethernet etc.
Ce type de machine entre en concurrence directe avec les superordinateurs SMP. Le grand nombre de nœuds qui composent une machine massivement parallèle doivent disposer d'une interconnexion à bande passante suffisante de manière à ne pas ralentir la communication internœuds, limitant le parti tiré de l'énorme potentiel de parallélisation.
Metacomputing
Le terme français pour traduire metacomputing est calcul réparti à grande échelle. Comme expliqué précédemment, l’idée est d’interconnecter des machines diverses comme des superordinateurs, des machines massivement parallèles ou des postes de travail divers pour fournir une machine virtuelle qui donne l’impression que l’on a à faire à une seule machine. L’idée du metacomputing est apparue lorsque les machines massivement parallèles n’ont plus suffit pour résoudre des problèmes de plus en plus gourmands en capacité de traitement. Les difficultés sont de fédérer les différentes ressources éloignées géographiquement, gérer les problèmes d’authentification, gérer le partage des données et des ressources, etc.
Un des systèmes le plus connu pour remplir cette tâche est Globus qui permet de créer une grille de calcul ou encore GRID computing (Globalisation des ressources Informatiques et des Données). Ainsi, depuis n’importe quel endroit de la grille, un programme ayant besoin de ressources peut en faire la demande à la grille sans avoir à se soucier d’où proviennent les ressources. Beaucoup de travaux de recherche sont en cours dans ce domaine, notamment à l'EPFL et les défis à relever sont nombreux.
Les méthodes de programmation utilisées dans les MMP consiste à échanger des messages ce qui implique, ici aussi, que la liaison entre les nœuds doit avoir une bande passante suffisante, ce qui n’est que rarement le cas lorsqu’on utilise des liaisons Internet. Une autre technique consiste à demander au nœud qui contient les données à traiter, d’effectuer le traitement et de renvoyer le résultat.
Exemple d'outils :
Mandriva
Il est intéressant de signaler que le projet CLIC 5 qui avait pour but de réaliser une distribution Linux™ pour grappe de calcul sur plate-forme Intel®.
|
Ce projet a permis la réalisation de grands calculateurs scientifiques en s'appuyant sur des logiciels dits 'libres' (licence GPL ou assimilée), Mandriva (ex. Mandrakesoft) s'étant fixé comme objectif la réalisation d’une distribution GNU/Linux pour grappe de machines, couvrant les besoins de déploiement, d'administration et de programmation d'une grappe dans le cadre d'une exploitation pour le calcul intensif. Le projet CLIC Linux est semble-t-il entre temps inclus dans les distributions Mandriva Cluster, entre temps |
Source :
James Frein, Cours sécurité, ESIG-Jura, 2008.
lue Gene/P
| BG/P main characteristics IBM Blue Gene/P Massively Parallel Computer ♦ 4 racks, one row, wired as a 16x16x16 3D torus ♦ 4096 quad-core nodes, PowerPC 450, 850 MHz ♦ Energy efficient, water cooled ♦ 56 Tflops peak, 46 Tflops LINPACK ♦ 16 TB of memory (4 GB per compute node) ♦ 1 PB of disk space, GPFS parallel file system ♦ OS Linux SuSE SLES 10. |
 Blue Gene/P Blue Gene/P© TICSIPD, 2010 |
 Blue Gene/P EPFL Lausanne Blue Gene/P EPFL Lausanne
© TICSIPD, 2010
|
|
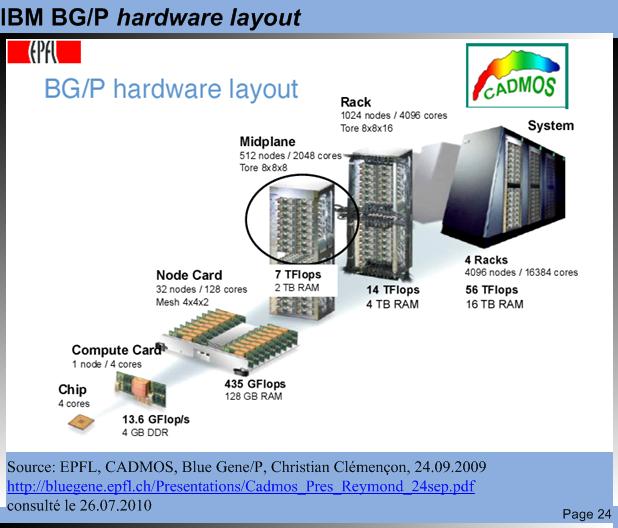 IBM BG/P hardware layout IBM BG/P hardware layout
© TICSIPD, 2010
|
|
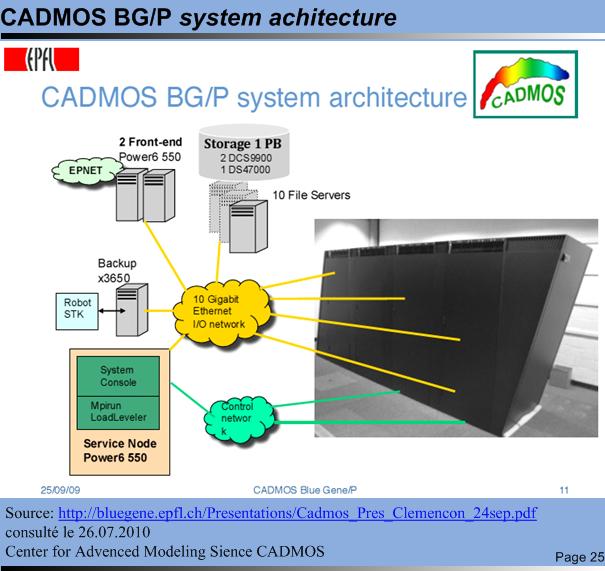 CADMOS BG/P system architecture CADMOS BG/P system architecture© TICSIPD, 2010 |
|
Source : EPFL, CADMOS, Blue Gene/P, Christian Clémençon, 24.09.2009
http://bluegene.epfl.ch/Presentations/Cadmos_Pres_Reymond_24sep.pdf consulté le 26.07.2010.
Ressources :
http://www.swing-grid.ch/index.php?option=com_frontpage&Itemid=1 consultée 25.07.2010
http://grid.epfl.ch/index.php consultée le 25.07.2010.
Évolution technologique et architectures internes
L’évolution technologique des composants utilisés pour la fabrication des ordinateurs a toujours été un point important dans l’évolution des capacités de traitement des systèmes informatiques. La loi de Moore dit que la puissance des processeurs double tous les 18 mois ! Cette loi étant relativement exacte, il faudrait néanmoins compter plutôt 24 mois. Si on analyse l’évolution des capacités de traitement des systèmes informatiques en faisant le parallèle avec l’évolution des microprocesseurs (ce qui n’est pas forcément exact mais qui est suffisant pour notre explication), nous constatons que la tendance suit la loi de Moore.
Mais compter uniquement sur l’amélioration technologique pure ou la finesse de d'écriture (gravure) par exemple, est une erreur car il est raisonnable de penser que la technologie, notamment celle basée sur les semi-conducteurs ne permettra pas d'améliorer indéfiniment la fréquence de travail donc la rapidité de calcul. Il faudra donc bien trouver d'autres facteurs sur lesquels agir. Les fréquences de travail des processeurs se sont stabilisées autour de 3 à 4 Ghz, par contre le nombre de microprocesseurs par chip double plus ou moins tous les deux ans.
<<En moyenne, le nombre d'unités de calcul par processeur double tous les deux ans, soit par l'augmentation du nombre de coeurs ou par des technologies comme l'hyperthreading, estime Gartner. Si l'on part du principe qu'en 2009, un serveur équipé de 32 processeurs à 8 coeurs permettrait de totaliser 256 unités de calcul, on atteindrait en 2011 512 unités de calcul (32 processeurs à 16 coeurs), puis 1024 en 2013.>> Guillaume Belfiore, 29.01.2009, http://www.clubic.com/actualite-254120-multi-core-performance-logiciel.html consultée le 26.07.2010.
<<Les caractéristiques physiques des matériaux que ce soit du silicium ou d’autres supports comme l’arséniure de gallium, (utilisés pour la réalisation des puces électroniques) ont des limites physiques que l’on ne peut dépasser. Certaines projections estiment que la technologie doit atteindre ses limites à l’horizon 2020). Mais ce qu’on fait de cette technologie et la manière de l'utiliser ne dépendent pas uniquement des techniques de mise en œuvre des matériaux. L’architecture interne que l'on veut mettre en place grâce à cette technologie joue un très grand rôle. Ainsi, les microprocesseurs sont le fruit d’architectures internes différentes qui influent grandement sur la capacité de traitement. Typiquement, tout informaticien a entendu parler des microprocesseurs RISC (Reduced Instructions Set Computer) et CISC (Complex Instructions Set Computer) qui sont deux stratégies d’implémentation différente du jeu d’instructions. La première (RISC) implémente un jeu d’instructions réduit mais en contrepartie on optimise l’exécution de ces instructions. Par contre la stratégie des processeurs CISC consiste à fournir un jeu d’instructions très étendu ce qui permet une simplification du logiciel destiné à ce type de processeurs.>> James Frein, Cours sécurité, ESIG-Jura, 2008.
Un peu de technologie
|
Avant toute chose, il convient de parler un peu de la technologie que l’on va trouver pour fabriquer un ordinateur et de définir les caractéristiques minimales de celui-ci. Un ordinateur est composé d’un CPU (Central Processing Unit) ou unité de traitement central qui interprète et exécute les instructions du programme. Dans la mémoire sont stockées les instructions et les données, le couple CPU / mémoire est appelé unité centrale. Le CPU est composé d’une unité arithmétique et logique (ALU) capable d’effectuer des opérations mathématiques et logiques et d'une unité de commande (contrôle) qui dirige les autres unités (ALU, mémoire, entrées/sorties). Les différentes unités sont reliées entre elles par un système appelé BUS6. |
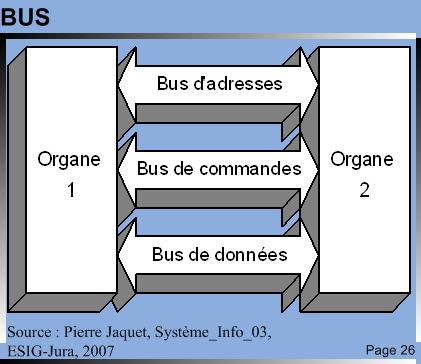 BUS BUS© TICSIPD, 2010 |
| C’est l’ensemble CPU, mémoire, bus de communication, organes d’I/O qui vont définir les performances de la machine et pas uniquement les performances intrinsèques du processeur. | 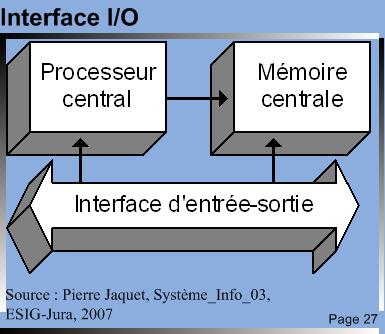 Interface I/O Interface I/O© TICSIPD, 2010 |
Localité spatio-temporelle
On part du principe qu’une information sera utilisée prochainement (donc qu’il faut la mettre dans le cache) si une des deux conditions suivantes est remplie :
⇒ Une information est référencée, elle a de fortes chances d’être à nouveau réutilisée bientôt, on parle alors de localité temporelle
⇒ Lorsqu’une information est référencée, les informations qui lui sont proches le seront certainement, on parle de localité spatiale.
A partir de ces constatations, on sait quelles sont les données qui statistiquement seront utiles, ce sont elles que l'on met dans le cache pour accélérer l’accès aux données.
Conclusions
Un ensemble formant un ordinateur performant est le fruit d’un assemblage entre divers composants (processeurs, mémoires, I/O) le tout relié par des organes d’interconnexion.
Parallélisme et limites des systèmes
Tirer profit des architectures parallèles, qu'elles soient à couplage étroit ou lâche, n'est pas chose aisée. Cela nécessite une programmation particulière dont certaines limites ne peuvent pas être dépassées. Croire qu'il suffit de rajouter des processeurs dans un système SMP ou de rajouter des nœuds dans un cluster est une vision bien raccourcie de la réalité.
Traitement séquentiel et parallèle
Si l'homme (ou la femme) est capable de faire certaines choses en même temps, par exemple parler et marcher, d'autres par contre doivent impérativement se succéder, par exemple verser de l'eau puis la boire. Il en est de même d'un programme. Par exemple, écrire "Hello World" dans un fichier texte.txt (existant et localisé) :
⇒ ouvrir et lire un fichier texte.txt sur le disque,
⇒ copier le contenu intégral de texte.txt dans la mémoire centrale,
⇒ afficher le contenu texte.txt,
⇒ positionner le point d'insertion et copier le texte avant et après celui-ci dans le cash,
⇒ écrire Hello World où toujours souhaité,
⇒ copier le texte modifié dans la mémoire centrale,
⇒ sauvegarder et fermer,
⇒ copier le texte de la mémoire centrale sur le disque et écraser le fichier sur le disque.
(Avec mes excuses aux puristes de l'algorithme si ma représentation de celle-ci est un peu imprécise.) Nous constatons, et c'est le but de ce petit algorithme, que les opérations doivent impérativement se succéder et que nous avons donc bien un traitement séquentiel. Une tâche doit être terminée pour que la suivante puisse commencer.
En fait, Philip Bernstein a défini ces conditions dès 1966 sous cette forme :
<<"Soit P1 et P2 deux programmes; on suppose que chacun des programmes utilise des variables en entrée (E1 et E2) et produit des valeurs en sortie (S1 et S2). Les programmes sont exécutables en parallèle (noté P1||P2) si, et seulement si, les conditions suivantes sont respectées : {E1 S2 = 0, E2 S1 = 0, S1 S2 = 0}>> James Frein, Cours sécurité, ESIG-Ju, 2008;
CHEVANCE René J. Servers multiprocesseurs, cluster et architecture parallèle, Editions Eyrolles, ISBN 2-212-09114-1, 2000, 538 pages, page 38.
En fait, l'amélioration des performances par la parallélisation des tâches à effectuer du fait de la structure séquentielle de certaines opérations est limitée.
Limites du parallélisme
La grille de calcul ci-dessous basée sur la loi d'Amdahl permet de voir la puissance utilisée par rapport à la puissance disponible en fonction du degré de parallélisation. Le nombre de processeurs a été choisi comme étant une puissance de deux car c'est généralement le cas en pratique.
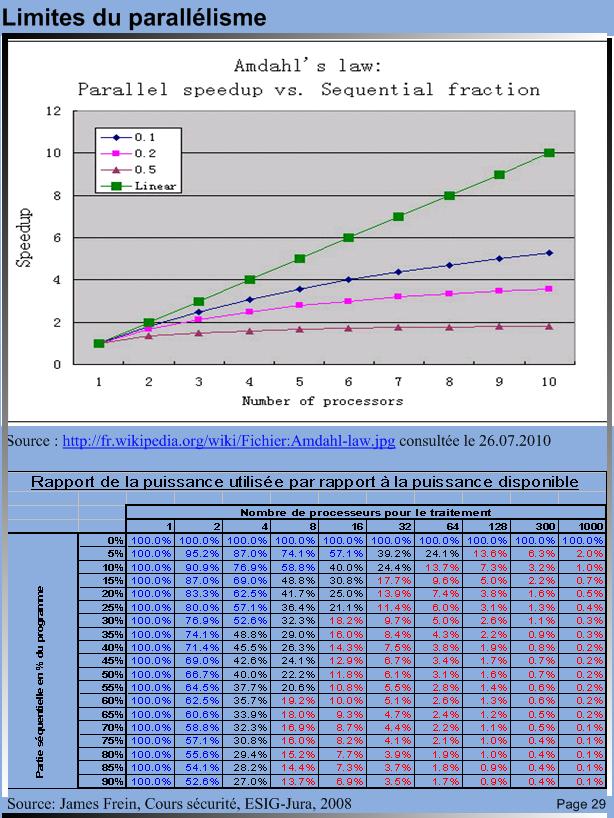 Limites du parallélisme
Limites du parallélisme
© TICSIPD, 2010
A la vue de ces résultats théoriques, la réalité est encore moins bonne, on comprend alors l'importance du développement de l'application. Celle-ci doit être spécialement écrite pour tirer parti des architectures parallèles pour profiter pleinement du gain en performance généré par le parallélisme.
Notions de processus
Cette partie traite de la problématique des processus lourds et légers. Les termes comme processus lourds, processus légers (thread), méthodes préemptives, méthodes d’ordonnancement seront abordées dans ce chapitre. Il a pour objectif de présenter succinctement ces concepts.
Définition d’un processus
|
Un processus est l’activité résultant de l'exécution d’un programme séquentiel, avec ses données, par un processeur. |
pA
|
|
Si l’on crée pour chaque tâche un processus (pA, pB, pC), ceux-ci peuvent être exécutés indépendamment l’une de l’autre. Donc, en fonction des méthodes d’allocation des processus au processeur, nous pourrons exécuter les processus dans l’ordre qui nous intéresse ou de manière simultanée grâce à l'exécution préemptive. |
|
||||||||
|
Ainsi, nous pourrons avec des stratégies de réquisition du processeur (préemptive, taille du processus) traiter les différentes tâches qui nous concernent de telle ou telle manière. Nous pourrons aussi tirer parti des configurations matérielles multiprocesseurs en allouant à chaque processeur un processus. |
Méthodes d’accès
Méthode FIFO
On parle de traitement par lot, batch ou train. Le premier processus arrivé est le premier servi (First In First Out). Les processus arrivent dans une file d’attente sont effectués les uns après les autres. Cette manière de faire revient un peu au même que de mettre toutes les tâches dans un processus plus grand et d'exécuter ce processus. Cette manière de faire pénalise les petits processus (si 10 petits processus sont situés dans la file derrière un seul gros processus, les 10 petits devront attendre la fin du gros).
Méthode du tourniquet
Chaque processus accède au processeur pour un temps déterminé à l’avance et cède sa place une fois son temps imparti écoulé. Il y a encore une notion de priorité due à l’ordonnancement dans la file d’attente. Cette méthode est dite préemptive car l’utilisation du processeur est retirée au processus au bout du temps imparti.
Méthode du tourniquet multi-niveaux
Cette méthode, semblable à la méthode du tourniquet, met en œuvre une notion de priorité. Chaque processus se voit attribuer un numéro de priorité qui le placera dans une file d’attente propre à son niveau. Tant qu’une file d’attente de priorité plus élevée qu’une autre contient des processus à effectuer, l’attribution du processeur se fera uniquement sur les processus de la file prioritaire.
Notons que les priorités peuvent être définies de différentes manières. Externes, fixées avant que le processus ne soit créé au niveau du système ou internes, c’est le système qui définit le niveau de priorité en fonction de critères prédéfinis.
Contexte d’un processus
C’est l'ensemble des informations dynamiques qui représente l’état d’exécution d’un processus. En fait, un processus interrompu parce qu’on passe la main à un autre doit maintenir son état de sorte que, lorsqu’il recevra à nouveau la main, qu'il puisse continuer de s’exécuter où il en était resté.
Processus lourds et processus légers
La communication entre processus lourds (vu par le système comme différents processus) est possible mais implique de passer par le système d'exploitation, ce qui est coûteux en terme de ressources et relativement lent par rapport à des processus légers ou threads.
|
Le principe est de mettre plusieurs threads à l’intérieur du même processus. Les threads partagent un espace d’adressage commun, ce qui implique qu’un mécanisme de synchronisation doit être disponible. Si deux threads veulent communiquer, ils n’ont pas à utiliser le système d’exploitation, ce qui est plus rapide. En programmation avec le langage Java, des processus lourds peuvent êtres créés avec l’une des méthodes exec de la classe java.lang.Runtime. Pour les processus légers, Java propose la classe java.lang.thread et fournit un système de synchronisation pour la manipulation des threads. |
Processus A
|
Le parallélisme malgré tout
Sur un serveur, comme sur un ordinateur, il y a toujours plusieurs processus qui fonctionnent simultanément et pas uniquement l'application qui nous intéresse. Les systèmes d'exploitation étant multitâches, plusieurs processeurs (core) peuvent travailler en parallèle et ainsi profiter des avantages du multi processeurs indépendamment des applications spécialement conçues pour tirer profit des architectures parallèles.
Nomenclature :
|
Schématiquement, l’hyper-threading consiste à créer deux processeurs logiques sur une seule puce, chacun doté de ses propres registres de données et de contrôle, et d’un contrôleur d’interruptions particulier. Ces deux unités partagent les éléments du cœur de processeur, le cache* et le bus système**. Ainsi, deux sous-processus peuvent être traités simultanément par le même processeur. Cette technique multitâche permet d’utiliser au mieux les ressources du processeur en garantissant que des données lui sont envoyées en masse. Elle permet aussi d’améliorer les performances en cas de défauts de cache (cache misses). consulté le 25.07.2010. |
|
2Threads |
Un thread ou tâche, processus léger, unité de traitement, unité d'exécution, processus allégé, représentent l'exécution d'un ensemble d'instructions du langage machine d'un processeur. Du point de vue de l'utilisateur, ces exécutions semblent se dérouler en parallèle. Le but est d'améliorer le remplissage du flot d'instructions du processeur et donc d'augmenter sa vitesse de traitement. consulté le 25.07.2010. |
3 API |
Une API (application programming interface) est une interface mise en œuvre par un logiciel qui permet d'interagir avec d'autres logiciels. L'API facilite l'interaction entre des logiciels différents. L'interface utilisateur de votre ordinateur vous facilitant l'interaction avec l'ordinateur est une API classique. consulté le 25.07.2010. |
|
MK-D32 Dual Core 1.6Ghz X2 Intel Dual Core Atom System, 945, VGA, LAN, COM, PS2, 6 USB, DDR2, SATA, Watchdog Timer. Optional Ram, 2.5in disk, Flash, SSD, wireless consulté le 25.07.2010. |
|
5 CLIC |
CLIC Linux → Mandriva : There are several public sector clients using Mandriva Clustering in North America. I do not have information for other Mandriva markets. For the most part, they use Mandriva's Professional Services for support for clustering, and I do not believe that they follow the club forum based on my conversations with them, and reviewing some of the postings. OSCAR has several clustering users on Mandriva, and there is a Canadian company that works with supporting OSCAR on Mandriva. The Mandriva Cluster using 9.2 was based on CLIC. The latest versions of Mandriva Cluster, which use Mandriva 10 as the core, I believe are not based on CLIC. Mandriva Cluster vs. others With Mandriva there is a high level of hardware testing and support, which may not be found with other solutions. Through Mandriva's relationships with Intel, HP and other partners we have a strong level of testing and hardware validation. Mandriva also offers additional support and consulting services to insure that your Cluster will be running for many years. These are factors that are important to Mandriva's enterprise and public sector clients. For many large clients, the issue is long-term stability and support. Insurance that commercially available support will be available, and someone who is responsible for the success of the project. If you are running a small cluster for non-critical applications and where human resources are inexpensive, Mandriva Cluster may not be the best solution. For critical applications that will be run over several years, where you need a "throat to choke" in the event that you have a problem or where you want to insure support in the event that you have changes in staffing, Mandriva and the Mandriva Cluster is a very nice solution. For most of Mandriva's enterprise clients, the choice is Mandriva vs. Red Hat AS, and for these clients, Mandriva is a cost effective and stable option. Source : http://forum.mandriva.com/viewtopic.php?t=48142&highlight=clic+cluster consulté le 26.07.2010 http://www2.mandriva.com/linux/server consulté le 26.07.2010 Autre source : http://www.theregister.co.uk/2002/11/05/clic_linux_for_clustered_environments/ consulté le 26.07.2010. |
|
Les bus relient aussi les éléments dont sont constitués les organes. Ils forment en quelque sorte une autoroute à voies multiples. Ils comprennent souvent 8, 32, 64 ou 128 fils électriques. La communication s’effectue en parallèle, ce qui veut dire qu’un signal est envoyé simultanément sur tous les fils du bus. |
Sources :
James Frein, Cours sécurité, ESIG-Jura, 2008
Pierre Jaquet, Cours machines & OS, ESIG-Jura, 2006.